这一节讲如何创建HTML5文档。
有人会想,这有什么好讲的?直接用Dreamweaver新建一个不就可以了?
但是往往说这种话的人只有一种-他绝对不是个有经验的人。
理由很简单,创建文档虽然很简单,但是日后的工作中,出现一些莫名其妙的问题,很可能就是文档基础结构出现了问题。而很大一部分人还不知道问题就出现在那里。
下面就来讲一下网页文档基础结构。
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>页面标题</title>
</head>
<body>
页面内容
</body>
</html>下面分别讲一下:
日常生活中,文档分很多种,word文档,excel文档,文本文档,网页文档…专业领域还有CAD文档,3DsMax文档等很多种文档。
为了有别于其它文档,网页文档在开头处标明,该文档类型为html,即网页文档。如下:
<!doctype html>然后,编码的时候会把所有页面所需代码写进以<html></html>包围的标签当中。
<!doctype html>
<html></html>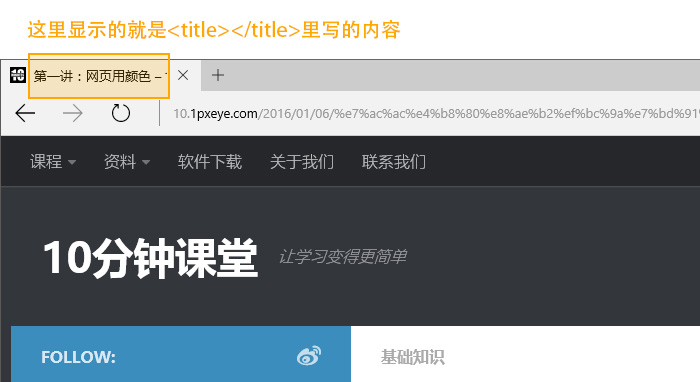
到了这一步,实际上一个HTML5文档已经被创建。
文档已被创建,下一步文档要有名字,要有标题。这样才会丰富。
页面标题会写在<title></title>标签当中。
而这个标题,并不是显示在页面当中的,而是显示在网页浏览器页面标签的位置。如下:
这个标签里的内容很重要。搜索引擎在浩瀚网络中搜集网页的时候,就是通过标题来收录网页的。如果什么都不写,或者是默认的标题《无标题文档》,那么搜索引擎很可能会跳过页面,不再进行收录。是非常不利于推广的。
由于,<title></title>里的内容不是直接显示在页面中,所以这样的内容默认是放在<head></head>标签里的。
如下:
<!doctype html>
<html>
<head><title>页面标题</title></head>
</html>那么<head></head>又是什么样的一个标签呢?
<head></head>标签用于定义文档的头部,它是所有头部元素的容器。<head></head>中的元素可以引用脚本、指示浏览器在哪里找到样式表、提供元信息等等。
文档的头部描述了文档的各种属性和信息,包括文档的标题。绝大多数文档头部包含的数据都不会真正作为内容显示给读者的。以后讲到的样式表,js文件默认都是在这里调用的。
而网页显示的内容都是放在<body></body>里的。
如下:
<!doctype html>
<html>
<head>
<title>页面标题</title>
</head>
<body>
页面内容
</body>
</html>到了这里,一个有身份,有内涵的页面被创建好了。但肤色不能代表一个人到底是属于哪个国家。说哪种语言。你认为对方是中国人的时候发现他说的是卡萨布兰卡语,完全是驴唇不对马嘴。这个时候对方最好是有更明显的标志,证明他是什么样的一个人。
言归正传,咱刚开始的时候,代码中有一段是:<meta charset=”utf-8″>
这段代码的作用是让页面以国际化编码来转义内容。这样,不管是中文还是英文还是日文的浏览器。无论是中国,美国还是日本的浏览器都能正确显示页面当中的内容。
否则:页面很可能会在某个浏览器上显示乱码。
所以有的时候,大家发现页面有乱码的时候,很可能是该网站的页面没有声明字符集(charset)类型。
咱又不能改人家网站,又想看准确的内容。那怎么办?
在浏览器的设置中找到“编码类型”,切换成“自动识别”,或者手动选择编码类型。
特殊内容:
看代码的时候大家会发现,为什么有的标签是配对的?如<title></title>为什么有的标签仅仅是单一的标签如:<meta>。
大家可以简单的理解为,配对的都是容器元素,容器里面还可以放更多的元素。
而单个的都是行内或是元信息。里面是不能添加的额外内容的。
例如以后讲到的图片的标签<img>。它就是单个的行内元素。
你可以想象,图片里还能插入图片么?不能,所以他是<img>。而不是<img></img>。
相关英语:
doctype = document type = 文档类型
head = 头
body = 身体
title = 标题
meta = 元语言(元信息)
html = hyper text markup language = 超级文本标记语言
评论区
发表新的留言
您可以留言提出您的疑问或建议。
您的留言得到回复时,会通过您填写的邮箱提醒您。